Identity Broker Forum
Welcome to the community forum for Identity Broker.
Browse the knowledge base, ask questions directly to the product group, or leverage the community to get answers. Leave ideas for new features and vote for the features or bug fixes you want most.

 Cannot compare dissimilar column types uuid and bigint at record column 1
Cannot compare dissimilar column types uuid and bigint at record column 1
All my UNIFYConnect adapters are showing the following error in the log, and all the Pending Changes are stuck in the adapter:
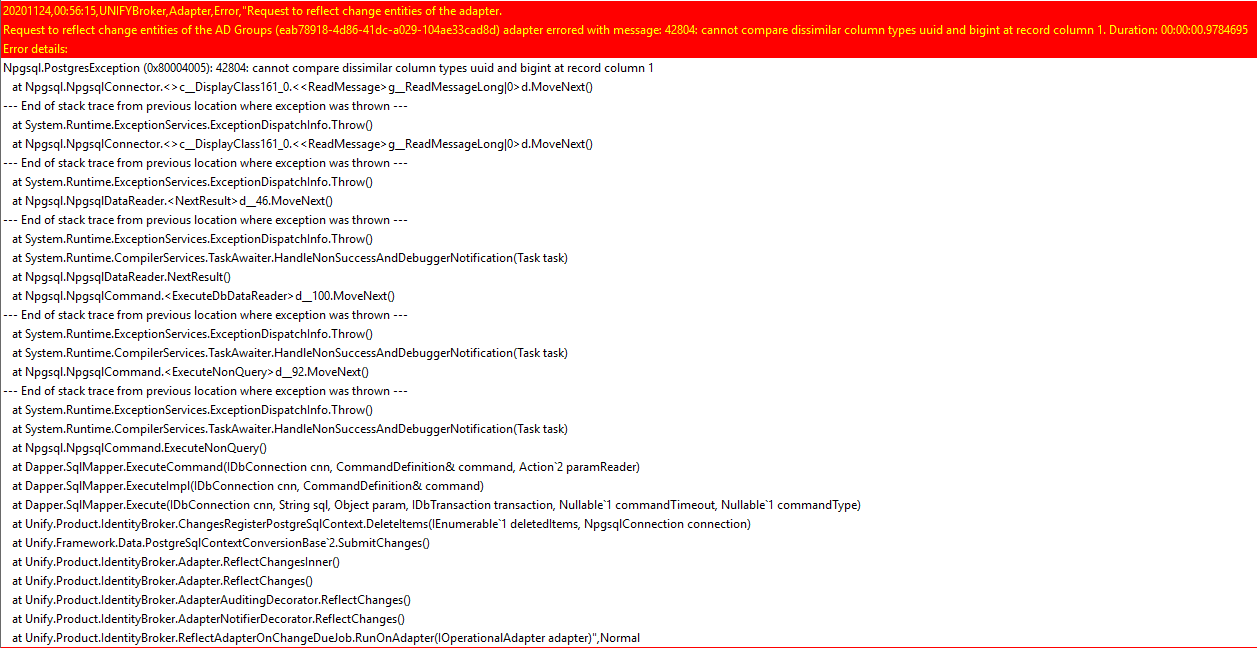
This is happening on the Netwealth UNIFYConnect instance.
Could you please investigate and fix or let me know what I've done wrong?

Patch attached for future reference, should go in the /Services/ directory.
 Multiple DC server support for the AD Agent
Multiple DC server support for the AD Agent
A client has asked that we configure UNIFYConnect to round-robin through a number of DC IP addresses. I can't find an explicit way to do this in the Agent documentation.
How can I meet this requirement? Create my own DNS entry with multiple IP addresses?
Hi Adrian,
There's no explicit support for multiple server entries in the AD Agent. As you've pointed out, the easiest way is to use a DNS entry which contains multiple IP addresses - either on the service side or the customer side.
 Remove LDAP adapter field name restriction for non-LDAP deployments
Remove LDAP adapter field name restriction for non-LDAP deployments
When deploying UNIFYBroker/Plus the LDAP name restriction for adapter field names is unnecessary - could you please offer a way to turn it off.

Upon review of this request, the modular way in which plugins and gateways interact require this restriction to still be in place, and would result in extra work if the solution was built and then an LDAP gateway added after the fact. Therefore the value in building this feature would not be realized in any measurable manner.
Email notifications based on old attribute values
Hi Matt,
In a past discussion with you I mentioned the importance of being able to know both the old and new value of an attribute when deciding to trigger an email notification, and this is an example of that.
Here’s an email requirement detail clarification just in from a UNIFYConnect customer:
“Speaking of emails, a manual process we may have missed. When a staff member is assigned an email address, we manually send them a welcome email from our CEO. If we provide the email content, etc, can you include this step in automation for new (email) users?”
Can you advise how I can detect that an email address attribute (imported from AD) has changed from blank to non-blank? Email addresses are assigned by Exchange policy so that’s the only way I can think of to detect and trigger the above action.

Matt wrote:
You could have a placeholder connector set up that contains ‘users with emails’, and only provision into that adapter/connector if they have an email address. Then run a post provisioning task that sends an email to them.
Or you could compare the entities to determine if a new value has been set in an email field, in one of your existing flows.
For the latter he is referring to the use of $sourceEntities and $targetEntities from PowerShell tasks.
Re-order Connectors and Adapters
In UNIFYBroker we could edit the connector and adapter extensibility files to re-order the connectors and adapters in the web UI. Could you please add a facility to do this in UNIFYConnect?
CSV connector with multivalued attributes
Is it possible to have multivalued attributes in a CSV connector?
Hey Adrian,
The CSV connector does support multi value attributes. If you wrap the mutli value column in quotes, and comma separate each value inside that column, the connector will import into a multi value field - as long as you set the connector schema to the appropriate multi value that you're after.
For example, a CSV like so:
id,name,data 1,user1,"value1,value2,value3,value4" 2,user2,"value1,value2,value3,value4" 3,user3,"value1,value2,value3,value4" 4,user4,"value1,value2,value3,value4" 5,user5,"value1,value2,value3,value4"
will return "value1, value2, value3, value4" as 4 different values inside the multi value string schema field "data".

Safety Catch Feature
In a MIM context we have been refining our Safety Catch to ensure that unwanted changes (not just deletes) are not replicated to target systems if the change count exceeds a threshold (% or raw number). The latest version is presently pending deployment for a long-term MIM site.
With the roll-out of more Broker+/UNIFYConnect implementations, an equivalent safeguard feature is now required - over and above the "connector delete threshold" native to UNIFYBroker itself. Until such a feature is available in a forthcoming release, a work-around should be considered for each implementation.
Join with Sliding Window with Most Relevant doesn't match record with NULL end date
UNIFYBroker v5.3.2 with Chris21.
Chris21 Person adapter is configured with a Join transformation to a Chris21 placement connector with a Sliding Window and type Relevant. A placement with a start date in the past and a NULL end date is not being selected (a NULL end date means ongoing placement, with no scheduled end date). Instead, the most recent placement with a non-NULL end date is selected.
Here is the placement data:
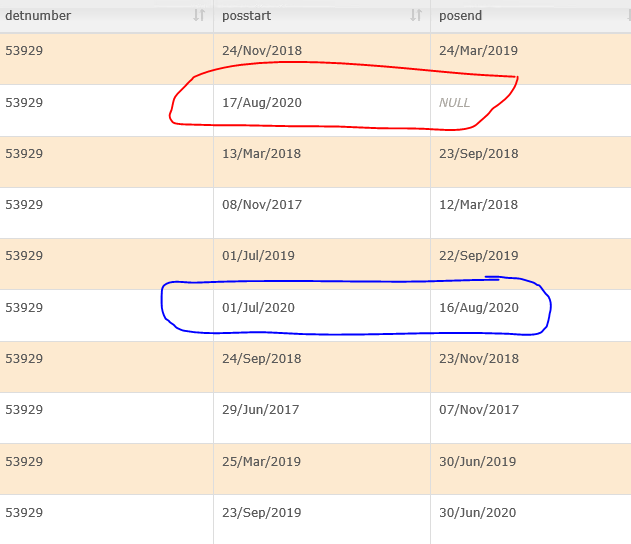
Here is the configuration:
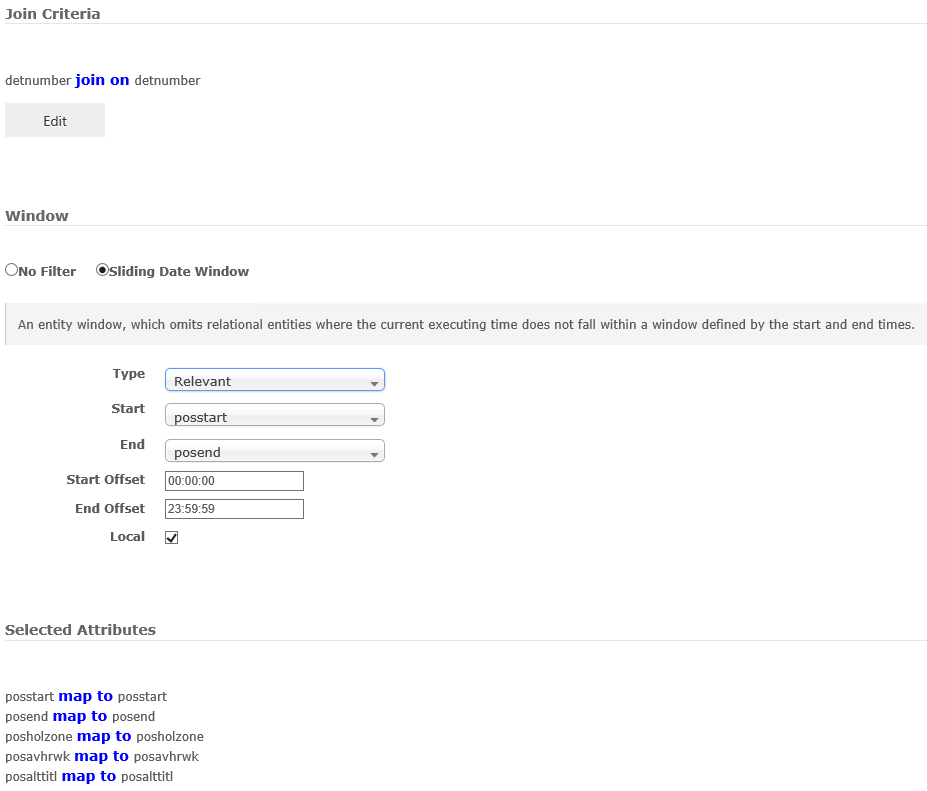
The transformed adapter data shows an incorrect posstart and posend (and all other selected attributes):
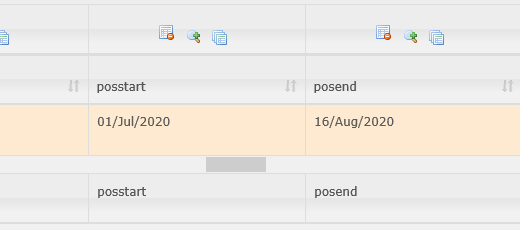
This problem did not occur in Identity Broker v4.
It may also be relevant to note that the 'First' or 'Priority Selection' radio box does not appear for the Relevant type. It used to appear for this transform and type in Identity Broker v4.
Hi Beau, sorry I thought I'd already responded to this. The problem was just a handful of records and Generate Changes cleared it. Please close this ticket.
Updating the Microsoft Office Enterprise agent from Azure Graph API to MS Graph API
The documentation for the Microsoft Office Enterprise agent refers to the Azure Graph API. Given that API is deprecated and will be turned off in 2022, are there plans to upgrade it to use the MS Graph API?

REST API endpoint for external Azure Access Request call-ins
In this morning's MS Identity Advisors session MS provided a clear indication that they are planning to move towards a call-out model for on-demand Access Request integration with external systems. To get ahead of the curve on this, we could look at offering an extensible REST API endpoint in UNIFYBroker.
Typical usage would be:
Azure sends UNIFYBroker a request for user "bobsmith" asking UNIFYBroker for a certain attribute for that user (e.g. department number) or asking UNIFYBroker to provide an answer to a question (such as "is this user allowed to get access to resource X at the moment?") UNIFYBroker responds and Azure uses that information to approve or deny an in-flight Access Request.
My suggested solution is that the request for user "bobsmith" (and/or "resource X") would map to a adapter record lookup, and the "answer" UNIFYBroker gives back would be the value of one or more fields for that matching record.
Hi Adrian
Since v5.2, Broker has included the OData gateway, which allows adapter entities to be queried via an OData REST API, which would cover the use case in your example. That said, since it's introduction I don't believe it's seen much, if any, real usage so may not fully support the types of request and filtering features that would be expected of it. Improving the OData gateway is definitely something we're interested in for future releases, so if you have the chance to try it out your feedback would be appreciated.
Also introduced in v5.2, the SCIM gateway provides a REST API conforming to the SCIM 2 specification, a standardized data schema for transmitting identity information via JSON payloads. The primary usage of this gateway thus far has been to connect Broker with Azure AD, which operates as a SCIM client to pull and push standardized users and groups from Broker. I mention it because it does support search and filtering features that would cover your example use case, however the rigid data structure it provides may be too limiting for non-SCIM-specific scenarios.
Customer support service by UserEcho
