Identity Broker Forum
Welcome to the community forum for Identity Broker.
Browse the knowledge base, ask questions directly to the product group, or leverage the community to get answers. Leave ideas for new features and vote for the features or bug fixes you want most.

 "Generate Changes" button for an individual object
"Generate Changes" button for an individual object
During development it would be very helpful to have a "Generate Changes" button on the SearchEntities page which executed a forced Generate Changes operation on just one object at a time.

This has been implemented and is available in the release of UNIFYConnect V6, which will be made available shortly.
 Dynamics CRM Upgrade 5.2.0.1 to 5.3.2.0, is not in the list of known agents
Dynamics CRM Upgrade 5.2.0.1 to 5.3.2.0, is not in the list of known agents
I'm doing an upgrade of Broker. The order of what I did
1. Uninstalled the CRM Agent out of Add/Remove Programs
2. Upgrade Broker from version 5.2.0.2 to 5.3.2.0
3. Installed CRM Dynamics agent v 5.3.2.0
4. Attempted to start the service and got the error.
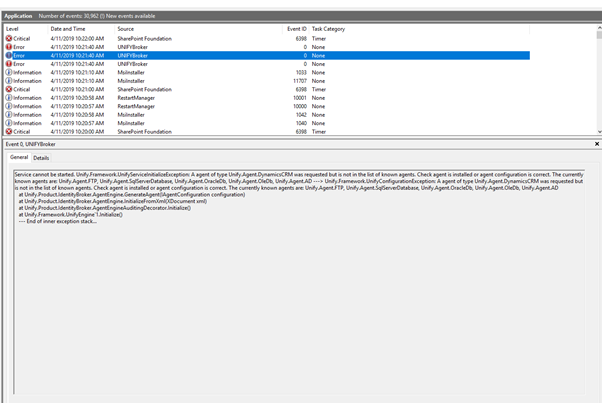
Double checked CRM Dynamics is now in the add/remove programs list. Rebooted the server. Problem still persists. Prompt support would be appreciated as I'm onsite doing an upgrade.

Adapter auto start
When a connector is stopped, adapters attached to it are also stopped (logically). But when you restart the connector again the adapter isn’t automatically restarted.
Would it be possible to implement a check that when an adapter is queried by FIM, if the adapter was turned off automatically it checks whether its dependencies are back on again and automatically turns back on? But if it was turned back on manually then it stays off and throws an error?

Option to send entity attribute level differences to PowerShell
As Identity Broker already has the ability to produce this, it would be good to have an option to have this pre-calculated for consumption in the PowerShell script.
WCAG 2.0 compliance
Allow for modular adapter transformations and logging providers
Currently we have the ability to use a provided interface to implement a custom connector that can synchronize data in a specified manner.
Understanding that we have the powershell logging and adapter transformation ability, I feel that it would be beneficial to give people the ability to write custom transformations and custom logging providers that can be loaded into IDB in the same way that custom connectors can be.
This would provide the ability for extended transformations that may be complex to be packaged and used as necessary, avoiding messy powershell scripts. It would also abstract the logging capabilities from the base IDB install, which means that any changes in provider functionality do not need a new release to be distributed (IE splunk changing its data endpoint).

Transformations are already pluggable, they are done in a similar manner to connectors. The difference being that the transformation generator is added into to adapter engine; and the UI uses ExtensibleTransformationController instead of ExtensibleConnectorController. There aren't instructions because no-one has been interested in this before, and we added PowerShell as the extensibility point.
The log writers are technically pluggable, in the service. However, they cannot be added into the UI - meaning they can't be configured. As with the transformation, we have added PowerShell as the extensibility point. I imagine the demand for extensibility in the logging is non-existent due to the PowerShell writer. Any log writers that would be of value would be incorporated into the product. Any breaking changes (as with your Splunk example) would be fixed up in the product, as with any breaking change.
Import with Scheduler disabled
Currently if the IDB scheduler is disabled, no connectors can run the full imports. When migrating between environments, sometimes you will copy the connector configurations across (which include a timed schedule for scheduled runs). However when doing data load for migration, you want to be able to run the specific connector full imports without other things running by themselves. Currently if the scheduler is disabled nothing can be run on the connector. Would be handy if connector imports could be run manually even with the scheduler disabled.
Connector Entity Viewing Headers
When viewing connector entities in IdB, there is a heading up the top which shows column names. Currently if the value of fields is large (such as an XML blob), you have to scroll to the bottom of the page to scroll vertically but then cannot see your column names which makes it difficult to know which column you're viewing.
Would it be possible to put the column names down the bottom of the table as well as up the top so you can see them at all times while scrolling?
Customer support service by UserEcho
