Join Transformation
Overview
The join is used to merge a selected connector into the adapter. Once join criteria have been defined, attributes of the joined connector can be selected to merge into the adapter, as well as a distinguished name for the entity.
Use Cases
The relational transformation can be used to accomplish the following:
- Joining data from multiple connectors together with data from the base connector and current adapter schema state, such as personal and address information
- Calculating manager, role and hierarchical relationships by joining the values contributed by other transformations against the base connector
Prerequisites
This transformation requires a relational connector.
Contribution
This transformation adds all mapped fields from the join connector and optionally the distinguished name of the joined entities based on a defined Distinguished Name template.
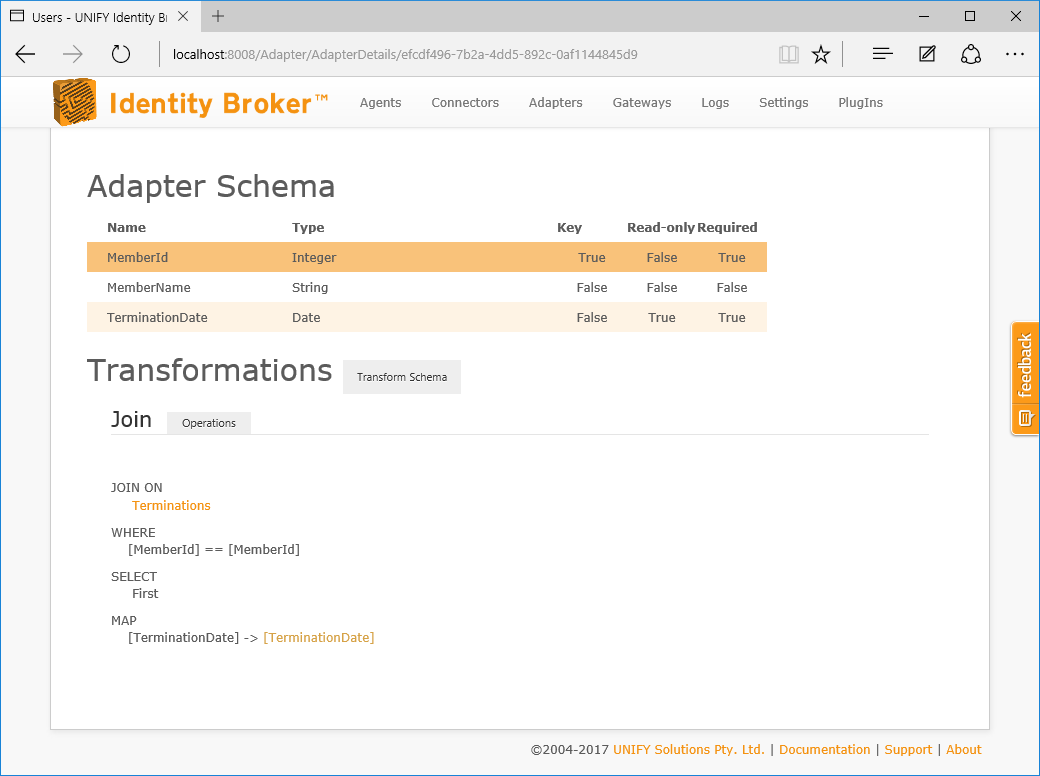
Configuration
The join transformation requires the following by way of configuration:
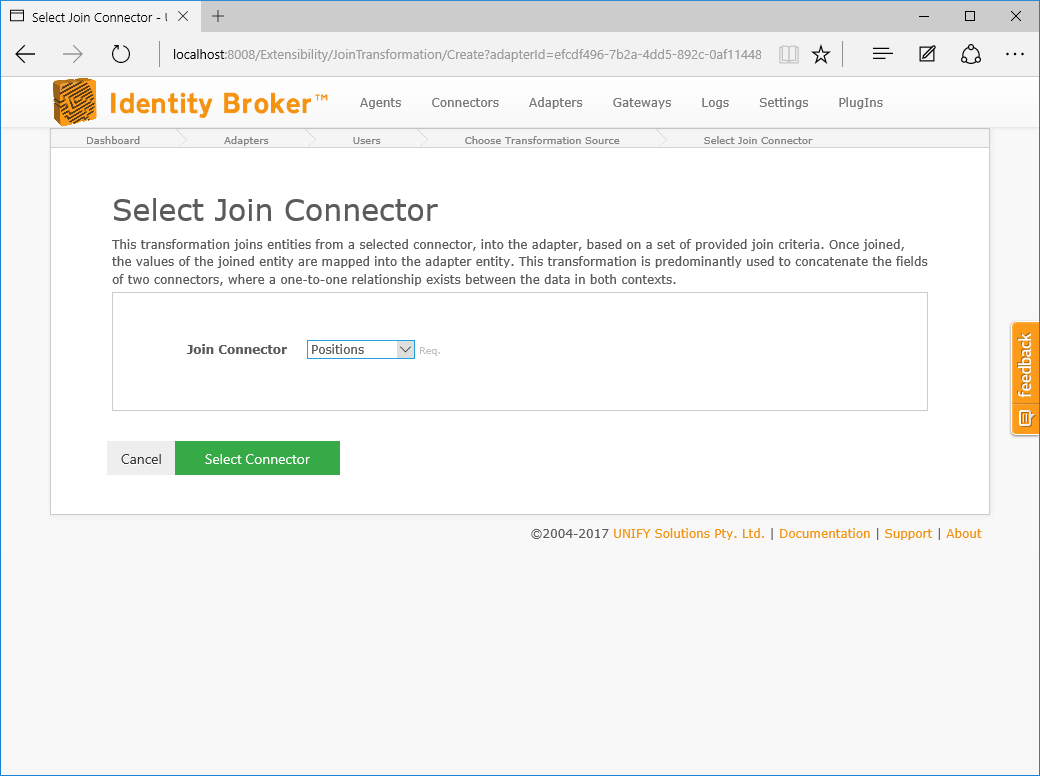
| Attribute | Description |
|---|---|
| Relational Connector | The relational connector to join on. |
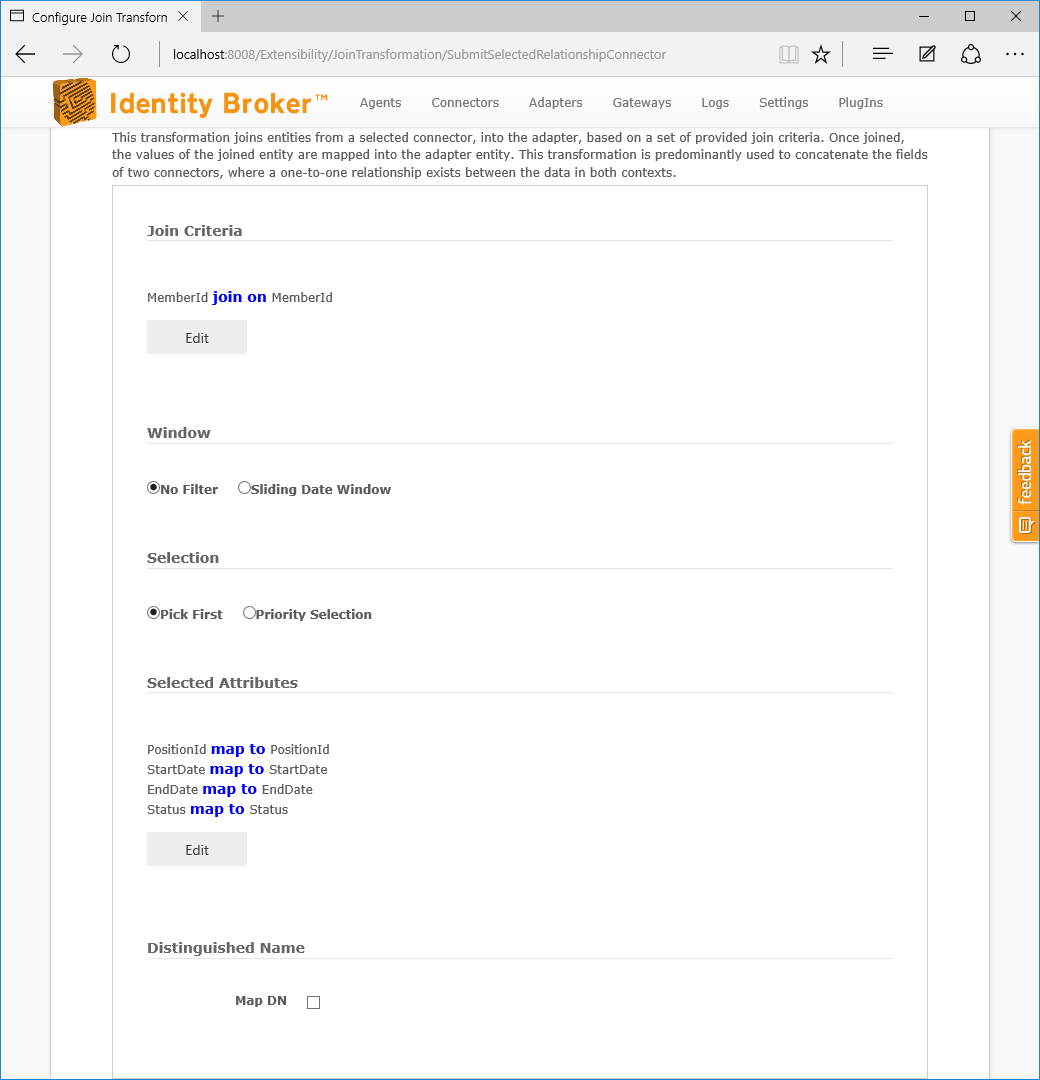
| Join Criteria | The one-to-many join criterion of the relationship. Each join is based on a one-to-one equality check. |
| Window | Defines the visible entities on the relationship side of the join. Refer to the particular window for more information. |
| Selection | The join transformation works on a one-to-one join basis. In circumstances where there are more than one entity found through the join, an entity needs to be selected. The default selection is to pick the first, but a priority selection can be configured. |
| Selected Attributes | The attributes to be mapped from the joined entity into the adapter entity. |
| Distinguished Name | In addition to the mapped attributes, a distinguished name can be generated for the entity, placed in a target field. |
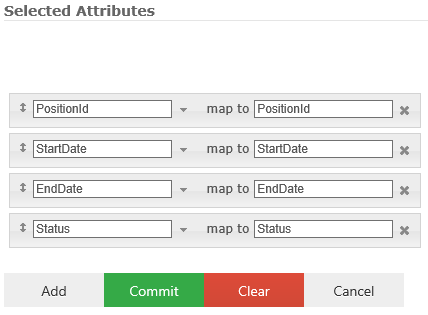
Selected Attributes
One to many column mappings can be added, which map fields from the relational connector schema into the adapter schema.
The following is an example implementation of the attribute mappings:
Window
The window defines the visible entities that may be joined on through the join connector.
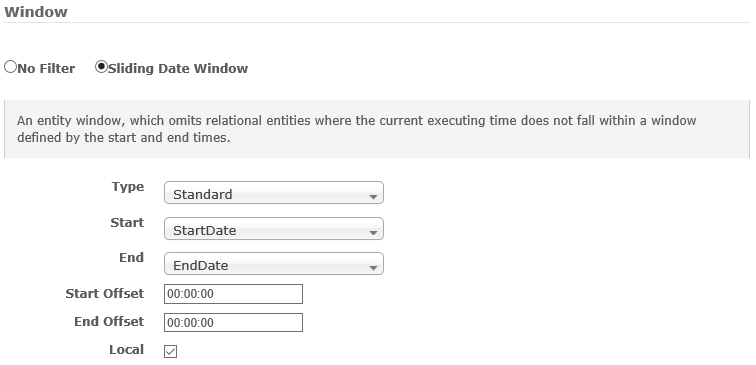
As of writing, the available windows are limited to either a sliding date window, or none.
The sliding date window defines a window in which entities on the joined connector will be filtered out dependent on a comparison between the start time and end time of the window.
| Attribute | Description |
|---|---|
| Type |
There are a number of types of sliding date windows. These types define how UNIFYBroker will determine whether the joined entities should be filtered out or not respective to the values of the window.
|
| Start | The start time for the sliding date window. |
| End | The end time for the sliding date window. |
| Start Offset | The offset to apply to the start time of the window. |
| End Offset | The offset to apply to the end time of the window. |
| Local | Whether to compare the times provided in their local time representations. |
When using a Date-typed fields for the start and end configuration options the values represent 12 am of that day.
For example: 10/2/2015 is regarded as 10/2/2015 12.00.00 am.
If the end date value is intended to be inclusive, that is the end date is the last day the window is active, a +1 day End Offset should be configured.
For example: With an inclusive end date of 12/6/2015 and a +1 day end offset, the window closes at 13/6/2015 12.00.00 am, the end of the 12th.
Selection
The join transformation works on a one-to-one join basis (values of only one entity are mapped). As a result, the join criteria should result in only one entity. In some cases, this may not be sufficient, in which case one of the joined entities will need to be selected. By default, this is just a process of picking the first (which works for one-to-one), but this is volatile/unreliable.
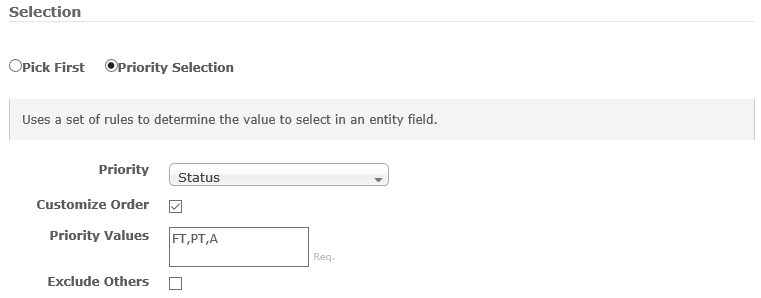
If a one-to-many join criteria is specified, a priority selection should be defined to reliably select from the available joined entities. The priority selection lets UNIFYBroker prioritize the entities joined by a particular field, and optionally by an ordered priority list of values for that field.
| Attribute | Description |
|---|---|
| Priority | The field to prioritize. This will be up to the implementation, but this could be something like a timestamp or particular flag. |
| Priority Values |
Only required if Customize Order is set. A comma-separated (,) collection of values describing the order of priority for values in the priority field. e.g. Priority: Status
Priority Values: FT,PT,A
Would prioritize an entity with a Status of FT, then PT, then A. |
| Exclude Others | Excludes items that are not included in the list of Priority Values. |
Change Processing
During the change detection process, a change will be flagged if any of the selected fields are updated in the relational connector.
Customer support service by UserEcho
