UNIFYBroker SQL Server Database Recommendations
Keeping in mind organisational policies surrounding the creation and maintenance of SQL Server databases, it is recommended that the latest released version of SQL Server is used, in addition to the following recommendations relating to the performance and security of the UNIFYBroker database.
Performance
For maximum database performance, it is recommended that the UNIFYBroker database files are located on a high speed disk without contention from other systems. Standard SQL Server best practices should be followed, including Optimizing tempdb Performance.
In addition, there are some settings that can be changed during the creation of the database that have the potential to greatly improve the performance of UNIFYBroker.
File Settings
The Initial Size setting for the Rows Data should be set to the size that the database is expected to grow to. This can be approximated at 20MB hard drive space per 1000 identities.
The Initial Size setting for the Log should be set to roughly 1/3 of the size of the Rows Data setting.
The Autogrowth setting should be changed from the default to avoid database fragmentation and reduce the chance of SQL Server from having to create space during the middle of an operation. A setting of 100MB generally avoids these problems. This setting should be seen as a contingency for unexpected growth, with monitoring and alerts allowing the database administrator to manually set the desired file size (see Considerations for the "autogrow" and "autoshrink" settings in SQL Server for best practices).
The Maximum File Size should be set to a reasonable limit to avoid the database filling the disk, whilst at the same time not restricting legitimate size increases.

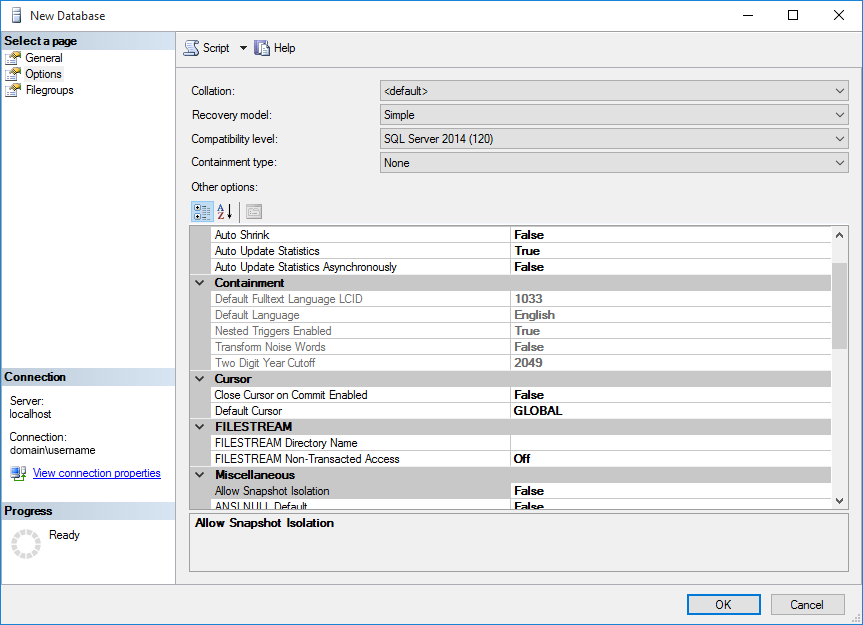
Options
- Recovery model - For an Identity Management solution that does not require point-in-time recoverability (connected systems can successfully resolve references to new objects by performing a full import), this setting should be set to Simple for maximum performance.
UNIFYBroker
For systems with high activity, it may be necessary to schedule recurring periods of inactivity, to allow database indexes to return to near 0% fragmentation. Please see Connector Overview for details on configuring Connector Schedules. Additional SQL Server Agent jobs may have to be created to force index rebuild or reorganise, as well as update statistics.
Data Integrity
Through the use of Configuring Microsoft Distributed Transaction Coordinator UNIFYBroker is designed to be resilient to data loss or failed database transactions. In the unlikely situation where data does become inconsistent/incorrect (for example MS DTC being disabled or misconfigured), UNIFYBroker will recover its data through the regular full import cycles - identity management platforms should be configured to allow for this to process to occur preventing import cycles from deleting missing data. Larger deployments may wish to employ other strategies for recoverability, such as backups (regular, incremental, and/or transactional).
Security
There are three options when securing the UNIFYBroker database:
- Create a new windows account to have the UNIFYBroker service run as. Provide this account with permissions to the Unify.IdentityBroker database; or
- Provide permissions to the
Unify.IdentityBrokerdatabase for the account under which UNIFYBroker is already running; or - Create a new Microsoft SQL Server account, that has permissions to the
Unify.IdentityBrokerdatabase. See Data Configuration for details on how to configure the connection.
SQL Server required permissions:
db_datareaderdb_datawriter
The above settings are generally the minimum required, however, some instances of SQL Server are set up in such a way that further permissions are required. Should UNIFYBroker log an exception pertaining to incorrect privileges whilst creating a temporary table, please grant db_owner to the appropriate account.
ALTER ROLE db_owner ADD MEMBER username
Maintenance Tasks
Statistics
The UNIFYBroker database should be maintained by a regular Update Statistics task, using the full scan option to avoid miscalculations. The task should be run as often as necessary to avoid performance degradation, or in cases where certain Connectors or Adapters are performing noticeably worse than others. A good starting point is to schedule the task to run nightly. Do not schedule after an index rebuild as it will result in duplicate work (after a reorganize is fine). An example script that updates statistics for all tables:
EXEC sp_MSforeachtable @command1="print '?'", @command2="UPDATE STATISTICS ? WITH FULLSCAN"
Indexes
As with ensuring that statistics are up to date, the indexes play an important role in the correct functioning of UNIFYBroker. At the very minimum a weekly Rebuild Index Task (Maintenance Plan) should be set up. This can be further optimized by first determining the level of fragmentation and then running the appropriate command, taking into consideration the SQL Server license restrictions (for example online rebuild only being available in the Enterprise edition). Performance should be monitored and the frequency of the task changed as appropriate. An example script that updates indexes on all tables:
EXEC sp_MSforeachtable @command1="print '?'", @command2="ALTER INDEX ALL ON ? REBUILD WITH (ONLINE=OFF)"
Microsoft Azure SQL Database
As SQL in Azure does not support all features available in the on-premises version, the above queries will not work as-is. A starting point to replace the index rebuild query is as follows:
DECLARE @Table varchar(255)
DECLARE TableCursor CURSOR FOR
SELECT '[' + table_schema + '].[' + table_name + ']' FROM information_schema.tables
WHERE table_type = 'base table'
OPEN TableCursor
FETCH NEXT FROM TableCursor INTO @Table
WHILE @@FETCH_STATUS = 0
BEGIN
EXEC('ALTER INDEX ALL ON ' + @Table + ' REBUILD')
FETCH NEXT FROM TableCursor INTO @Table
END
CLOSE TableCursor
DEALLOCATE TableCursor
Customer support service by UserEcho

During the initial load of some 18K rows into a SQL table via an export from FIM via an IdB4 adapter, I found that even with the above best practices followed, including indexing fully defragmented, and stats updated (both on IdB and target SQL databases), I still ran into strife.
What happened was the export rate dropped dramatically over a 7 hour period, to the point where at best I was getting 5 inserts every 2-3 minutes!!! After 7 hours I only had 4K exports and 13K still to go ... I had to make changes!
Here's what I had to do to fix this:
With the db tuned and the integrity of IdB recovered, I was able to export the remaining records to SQL OK. I could have probably let things go at step #7 but I didn't want to take any chances because this was happening during business hours and already causing delays.
What I don't know, at this point, is what I could have done differently to get a better result in the first place. It seems like step#1 might have been the best option - but this shouldn't be necessary. I don't recall having these issues in non-production ...
Any suggestions for next time?
Possibly not for v4.x. If it was related to a SQL "feature" called parameter sniffing - there is a workaround that clears out the proc cache before queries are executed. But that would involve some profiling and testing to confirm whether this is the case.
In v5+ - this would likely perform much better due to the batched exports
Further to the above, with the export of the last 3629 rows in 21 minutes (a vast improvement, but still slower than I anticipated), I noticed that the IdB service was still very busy processing. I figured that this behaviour is probably the root cause of things gumming up in the first place ... so I did this on the IdB host:
Looking at the logs I can see hundreds of repeats of the following process:
Why is this process happening ONE RECORD AT A TIME? How can it be sped up? What happens if I restart the service at this point and the restart attempt times out again?
This is a limitation in FIM ECMA1 - no longer an issue now that ECMA2 supports batched operations.
OK I understand this process much better now - and this will help me (and OTHERS I expect) HEAPS in planning for next time. I already knew about the batch limitation, but didn't realise its impact trickled down this deep into the IdB process.
Needless to say fragmentation after the 3.5K exports was back up to around 99% once more.
Is there ANYTHING that can be done (reduce logging, accumulating exports in batches somehow, ...) in IdB4 because an upgrade to IdB 5 is such a big deal due to replacement of the FIM MAs themselves?